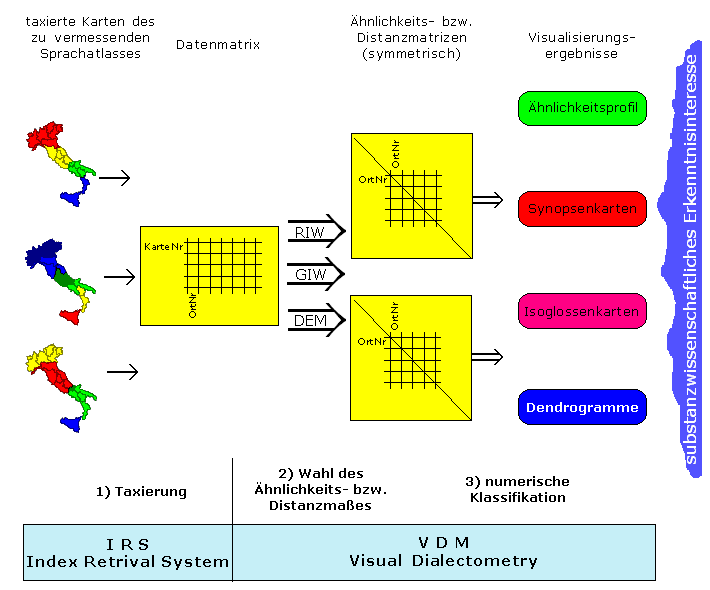
Die dialektometrische Verfahrenskette
vgl. GOEBL, Hans (1998,
Figur 1: Flußdiagramm dialektometrischer Verfahren, S. 978).
1) Taxierung
Bei der Taxierung geht es darum, die Antworten einer Sprachatlaskarte in
Typen, i.e. Taxate zusammenzufassen. Dabei kann man die zu klassifizierenden
Daten (Taxandum) jeweils nach phonetischen, morphosyntaktischen oder lexikalischen
Kriterien vermessen (taxieren). Das Ergebnis ist eine Liste, die jeder
Ortnummer der Karte ein Taxat bzw. dessen Taxatnummer zuordnet. Jede Liste
einer taxierten Sprachatlaskarte bildet einen Zeilenvektor der nominalskalierten
Datenmatrix.
Die von Linguisten durchgeführten händische Taxierungen folgen
in der Regel folgendem Ablauf:
-
Kriterien festlegen (z.B. lexikalisch, phonetisch).
-
Liste der verschiedenen Typen (Taxate) aufstellen und Nummern vergeben.
-
Zuweisung der einzelnen Antworten auf der Karte zu je einem Taxat, es entsteht
die Ortnummer-Taxatnummer-Liste.
Daneben gibt es ein Programm zur automatischen Taxierung (I
R S), das z.Z. an Karten des ALD-I erprobt wird.
2) Wahl des Ähnlichkeits- bzw. Distanzmaßes
Der erste Schritt bei der Erforschung von Relationen in der Datenmatrix
besteht in der Vermessung der Ähnlichkeiten bzw. Abständen zwischen
den Orte (Variablen oder Spaltenvektoren der Datenmatrix). Dazu kann zwischen
verschiedenen Ähnlichkeits- bzw. Distanzmaßen ausgewählt
werden, die jeweils den Abstand zwischen Orten, d.h. zwischen Spaltenvektoren
definieren:
-
RIW - relativer Identitätswert (simple matching coefficient)
-
GIW - gewichteter Identitätswert; hier geht die Frequenz der einzelnen
Taxate in die Berechnung mit ein
-
DEM - durchschnittliche Euklidische Distanz
Die Ergebnisse der Distanzberechnung, i.e. die Ähnlichkeit jedes Ortes
(Variable) zu allen anderen Orten, werden als Prozentwerte in eine Distanzmatrix
eingetragen. Diese ist wegen der Reflexivität der in der Dialektometrie
verwendeten Ähnlichkeitsmaße eine symmetrische N * N Matrix
(d.h. gleiche Werte über und unter der Diagonale) mit N=Anzahl der
Orte. Aus einer Datenmatrix können durch Wahl verschiedener Ähnlichkeitsmaße
mehrere Matrizen erzeugt werden.
3) Numerische Klassifikation
Solchermaßen erzeugte Ähnlichkeitsmatrixen können in VDM
unmittelbar visualisiert werden; im einfachsten Fall als Ähnlichkeitsprofil:
Eine Zeile der Ähnlichkeitsmatrix enthält die dialektale Ähnlichkeit
des Referenzorts (nächste Abb.: Sartrouvill, ALF Nr. 227, Distanzmaß
RIW) zu allen andern Orten. Auf der Karte erscheinen Nachbarn mit hoher
Ähnlichkeit (84-92%) rot, weiter entfernte in orange, gelb usw. bis
zu den weitest entfernten in dunkelblau. Zur Segmentierung der Ähnlichkeitswerte
bietet VDM 3 Segmentierungsalgorithmen an, die sich in den letzten 15 Jahren
in der Dialektometrie etabliert haben hier wird MINMWMAX verwendet mit
gleicher Segmentbreite unter bzw. über dem Mittelwert.
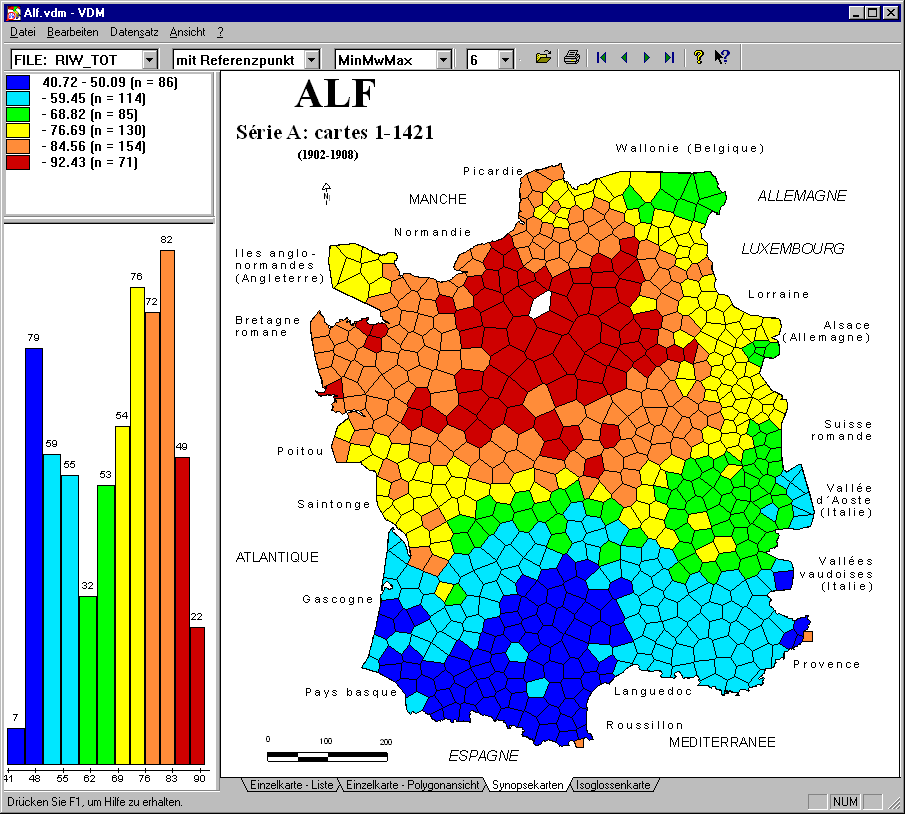
Der Wechsel des Referenzorts durch Klick in die interaktive Karte zeigt
das Ähnlichkeitsprofil eines anderen Referenzorts. So lassen sich
Dialektlandschaften erforschen. Man findet große Flächen mit
vielen unmittelbaren Nachbarn (z.B. die bekannte Opposition Nord-Süd,
langue d'oil-langue d'oc), Enklaven mit wenigen Freunden (z.B. Aosta),
Übergangszonen und sogar Sprachinseln.
Darüber hinaus sind synoptische Auswertungen der Ähnlichkeitsmatrix
möglich (Minimum, Maximum, Mittelwert, Sandardabweichung, Schiefe,
Clusteranalyse - in Arbeit) sowie Visualisierungen mit verschiedenen Kartentypen
(Ähnlichkeitsprofil - siehe oben, Isoglossenkarten, Dendrogramm der
Clusteranalyse in Arbeit).
Bemerkungen und Vorschläge bitte an:
Edgar Haimerl
Letzte Änderung / aggiornato al: